Introducing the Event-Driven Ansible & Demo
-
 Jin Zhang
Jin Zhang
- Ansible, Ansible resources, Automation
- January 26, 2023
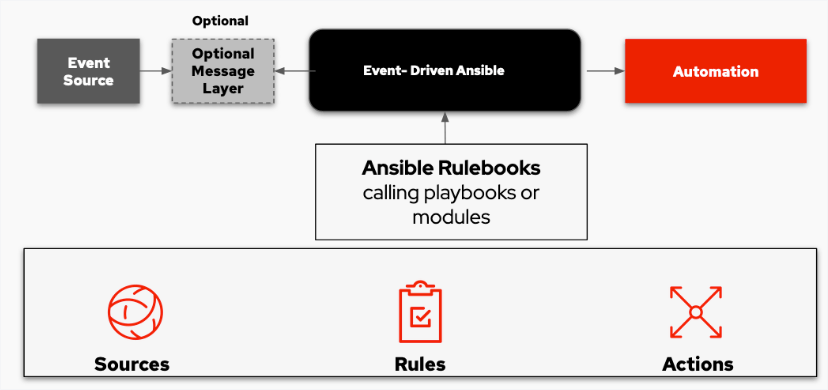
In AnsibleFest 2022, Red Hat announced an exciting new developer preview for Event-Driven Ansible. Event-Driven Ansible is a new way to enhance and expand automation. It improves IT speed and agility while enabling consistency and resilience.
When this event occurs, Event-Driven Ansible matches the rule to the “event” and automatically implements the documented changes or responses in the rulebook to handle the event.
There are three major building blocks in the Event-Driven Ansible model, sources, rules, and actions that play key roles in completing the workflow described above:
- Sources are third-party vendor tools that provide the events. They define and identify where events occur, then pass them to Event-Driven Ansible. Current source support includes Prometheus, Sensu, Red Hat solutions, webhooks, and Kafka, as well as custom “bring your own” sources. In this demo, I use Kafka.
- Rules document your desired handling of the event via Ansible Rulebooks. They use familiar YAML-like structures and follow an “if this then that” model. Ansible Rulebooks may call Ansible Playbooks or have direct module execution functions.
- Actions are the result of executing the Ansible Rulebook’s instructions when the event occurs.
Demo – Devent Driven Monitoring
This demo shows how to monitor the rpm package installation activities and prevent ‘illegal’ package installation.
Environment Setup
There are 2 major components:
- Apache Kafka – provide the events.
- Ansible-rulebook – Listening to the events, detecting the ‘illegal’ rpm, and triggering the playbook to delete the detected rpm.
APACHE KAFKA
Prepare one RHEL 8 server and set up a standard FQDN hostname ‘kafka.example.com’.
Install APACHE KAFKA
Reference https://kafka.apache.org/quickstart
Download Kafka from the below link:
https://www.apache.org/dyn/closer.cgi?path=/kafka/3.3.1/kafka_2.13-3.3.1.tgz
extract install tgz file
$ tar -xzf kafka_2.13-3.3.1.tgz
$ cd kafka_2.13-3.3.1
Start the ZooKeeper service
Run the following commands in order to start all services in the correct order:
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Start the Kafka broker service
Open another terminal session and run:
$ bin/kafka-server-start.sh config/server.properties
Import data as a stream of events with Kafka Connect
First, make sure to add connect-file-3.3.1.jar to the plugin.path property in the Connect worker’s configuration.
Edit the config/connect-standalone.properties file, and add or change the plugin.path configuration property match the following, and save the file:
# grep -v "^#" config/connect-standalone.properties
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
plugin.path=libs/connect-file-3.3.1.jar
Configure the source file ‘/var/log/dnf.log’ as below:
# grep -v "^#" ./config/connect-file-source.properties
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=/var/log/dnf.log
topic=connect-dnf
Configure the sink file as below:
# grep -v "^#" config/connect-file-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=dnf.sink.txt
topics=connect-dnf
Start two connector
Next, I will start two connectors running in standalone mode, which means they run in a single, local, dedicated process. We provide three configuration files as parameters. The first is always the configuration for the Kafka Connect process, containing common configurations such as the Kafka brokers to connect to and the serialization format for data. The remaining configuration files each specify a connector to create. These files include a unique connector name, the connector class to instantiate, and any other configuration required by the connector.
Open another terminal session and run:
$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
Events from the dnf log file
Note that the data is being stored in the Kafka topic connect-dnf, so we can also run a console consumer to see the data in the topic (or use custom consumer code to process it):
# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-dnf --from-beginning
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T04:51:21-0500 INFO --- logging initialized ---"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T04:51:21-0500 DDEBUG timer: config: 6 ms"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T04:51:22-0500 DEBUG Loaded plugins: builddep, changelog, config-manager, copr, debug, debuginfo-install, download, generate_completion_cache, groups-manager, needs-restarting, playground, product-id, repoclosure, repodiff, repograph, repomanage, reposync, subscription-manager, uploadprofile"}
...
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: checkpolicy-2.9-1.el8.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: grub2-tools-efi-1:2.02-142.el8_7.1.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: kernel-4.18.0-425.10.1.el8_7.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: kernel-core-4.18.0-425.10.1.el8_7.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: kernel-modules-4.18.0-425.10.1.el8_7.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: policycoreutils-python-utils-2.9-20.el8.noarch"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: python3-audit-3.0.7-4.el8.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: python3-libsemanage-2.9-9.el8_6.x86_64"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: python3-policycoreutils-2.9-20.el8.noarch"}
{"schema":{"type":"string","optional":false},"payload":"2023-01-14T18:21:37+0800 DEBUG Installed: python3-setools-4.3.0-3.el8.x86_64"}
...
The connectors continue to process data, so we can add data to the file and see it move through the pipeline:
$ echo Another line>> /var/log/dnf.log
You should see the line appear in the console consumer output.
Ansible-rulebook
Prepare one RHEL 9 server
Install ansible-rulebook
Reference: https://github.com/ansible/ansible-rulebook/blob/main/docs/installation.rst
dnf --assumeyes install gcc java-17-openjdk maven python3-devel python3-pip
export JDK_HOME=/usr/lib/jvm/java-17-openjdk
export JAVA_HOME=$JDK_HOME
pip3 install -U Jinja2
pip3 install ansible ansible-rulebook ansible-runner wheel
pip3 install aiokafka
Install collection ansible.eda
ansible-galaxy collection install community.general ansible.eda
Inventory
# cat inventory.yml
kafka.example.com ansible_user=root
Rule-Book – ‘kafka-dnf.yml’
# cat kafka-dnf.yml
- name: Read messages from a kafka topic and act on them
hosts: kafka.example.com
## Define our source for events
sources:
- ansible.eda.kafka:
host: kafka.example.com
port: 9092
topic: connect-dnf
group_id:
rules:
- name: receive event
condition: event.schema.type == "string"
## Define the action we should take should the condition be met
action:
run_playbook:
name: dnf-event.yaml
delegate_to: localhost
It listens on the topic ‘connect-dnf’ from port 9092 on server ‘kafka.example.com’. The new line in the ‘dnf.log’ will trigger a new event. Ideally, I should use ‘condition:’ to detect the expected event and call the playbook. At this moment, the ‘condition:’ does not support complicated operations, like regex string match. I pass the entire event content to the playbook ‘dnf-event.yaml’ for condition filtering.
Playbook – ‘dnf-event.yaml’
# cat dnf-event.yaml
---
- name: Analyze the dnf event.payload
hosts: kafka.example.com
gather_facts: false
vars:
rpm_black_list:
- telnet
- traceroute
tasks:
- set_fact:
event_content: "{{ event.payload.replace('\"', '') }}"
- debug:
msg: "{{ event_content }}"
- name: check if rpm listed in blacklist
command: /usr/bin/python3
args:
stdin: |
import re
in_blacklist = False
search_pattern = "^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\+\d{4}\s+DEBUG\s+Installed:\s+(.+?)$"
try:
installed_rpm = re.search(search_pattern, "{{ event_content }}").group(1).strip()
except:
print('no package installed')
else:
for rpm in {{ rpm_black_list}}:
if re.search(rpm, installed_rpm):
in_blacklist = True
print(installed_rpm)
print(in_blacklist)
register: results
- name: Remove the RPM in blacklist
ansible.builtin.yum:
name: "{{ results.stdout_lines[0] }}"
state: absent
when: results.stdout_lines[-1] | bool
The below variable includes the package name in the blacklist
vars:
rpm_black_list:
- telnet
- traceroute
The search pattern is used to detect package installation events:
search_pattern = "^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\+\d{4}\s+DEBUG\s+Installed:\s+(.+?)$"
Sample package installation events:
2023-01-17T21:11:19+0800 DEBUG Installed: telnet-1:0.17-76.el8.x86_64
The python code is to detect the package installation event and check if the installed package is on the blacklist:
try:
installed_rpm = re.search(search_pattern, "{{ event_content }}").group(1).strip()
except:
print('not package installed')
else:
for rpm in {{ rpm_black_list}}:
if re.search(rpm, installed_rpm):
in_blacklist = True
print(installed_rpm)
The playbook code to remove the illegal package:
- name: Remove the RPM in blacklist
ansible.builtin.yum:
name: "{{ results.stdout_lines[0] }}"
state: absent
when: results.stdout_lines[-1] | bool
Start Ansible Rulebook
$ ansible-rulebook --rulebook kafka-dnf.yml -i inventory.yml --verbose

Installed ‘illegal’ package ‘telnet’
Detect the target event and trigger uninstall playbook
In the below screen capture
The event ‘2023-01-26T17:58:58+0800 INFO Installed products updated.’ is not what we look for. The task ‘Remove the RPM in blacklist’ is skipped.
The event ‘2023-01-26T17:58:58+0800 DEBUG Installed: telnet-1:0.17-76.el8.x86_64’ is what we look for. The task ‘Remove the RPM in blacklist’ is trigged.

Verify the package ‘telnet’ status

Summary
An event-driven structure is based on events, which signal to interested parties. Events are happening all the time across all industries.
In an event-driven structure, there are producers and consumers. Producers trigger events sent to interested consumers as messages through an event channel, where they are processed asynchronously. Producers and consumers don’t have to wait for each other to begin the next task, as producers are loosely coupled or completely decoupled from recipients.
Decoupling improves scalability, as it can separate communication and the logic between producers and consumers. The playbook developer on the consumer side does not need to have an inside view of producers, and vice-versa. A publisher can avoid bottlenecks and remain unaffected if its subscribers go offline or their consumption slows down.
Jin Zhang
I’m Jin, Red Hat ASEAN Senior Platform Consultant. My primary focus is Ansible Automation (Infrastructure as Code), OpenShift, and OpenStack.
Note
Disclaimer: The views expressed and the content shared in all published articles on this website are solely those of the respective authors, and they do not necessarily reflect the views of the author’s employer or the techbeatly platform. We strive to ensure the accuracy and validity of the content published on our website. However, we cannot guarantee the absolute correctness or completeness of the information provided. It is the responsibility of the readers and users of this website to verify the accuracy and appropriateness of any information or opinions expressed within the articles. If you come across any content that you believe to be incorrect or invalid, please contact us immediately so that we can address the issue promptly.